

We define a ZDD
\[Z\]
to be any directed acyclic graph such that:\[\top\]
(the "TRUE" node), or:
\[\bot\]
(the "FALSE" node).
\[v\]
. This label
need not be unique.
\[v\]
. Thus we can omit arrowheads in diagrams
because the edge directions can be inferred from the labels.
\[\bot\]
node.
\[Z\]
an unreduced ZDD, if a HI edge points to \[\bot\]
or the last
condition fails to hold.In our first example, the universe
\[U\]
was the letters of the alphabet. More
generally, we consider a universe of size \[n\]
, number the elements from 1 to
\[n\]
, and refer to an element by this number.The dag rooted at any node in a ZDD is itself a valid ZDD. Thus we expect straightforward recursive descriptions of many ZDD algorithms and properties. Indeed, anyone comfortable with dynamic programming will feel at home with ZDDs.
Representing a family
Let\[F\]
be a ZDD. Let \[v\]
be its root node. Then:\[v = \bot\]
then there can be no other nodes and \[F\]
represents \[\emptyset\]
,
the empty family.
\[v = \top\]
then there can be no other nodes and \[F\]
represents the family
containing just the empty set: \[\{ \emptyset \}\]
. We call this the unit family,
and denote it by \[\epsilon\]
.
\[v\]
has two children. Let \[v_0\]
be the LO node, and \[v_1\]
be the
HI node. Let \[F_i\]
be the family represented by the ZDD rooted at \[v_i\]
which
is known by inductive assumption.
Then \[F\]
represents the family
\[ F_0 \cup \bigcup_{\alpha\in F_1} \alpha \cup \{v\} .\]
In other words, as in real life, we divide the world between the haves and the
have-nots: on the LO branch we have the sets in \[F\]
that don’t contain \[v\]
:\[ F_0 = \{ \alpha : \alpha \in F, v \notin \alpha \} \]
and on the HI branch we have the sets in \[F\]
that do contain \[v\]
, but we
remove the \[v\]
before recording them:\[ F_1 = \{ \alpha\setminus\{v\} : \alpha \in F, v \in \alpha \} \]
Some examples: 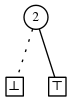
The above is the family
\[\emptyset \cup \{\emptyset \cup \{2\}\} = \{ \{2\}\}\]
.
This is \[e_2\]
, an elementary family.
Elementary families are those of the form \[\{\{n\}\}\]
, and denoted by \[e_n\]
.More family photos:
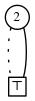
\[\{\emptyset\} \cup \{\emptyset \cup \{2\}\} = \{ \emptyset, \{2\}\}\]
.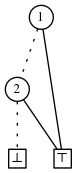
\[\{ \{2\} \} \cup \{ \emptyset\cup \{1\} \} = \{ \{1\}, \{2\}\}\]
.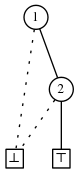
\[\epsilon \cup \{ \{1\} \cup \{2\} \} = \{ \{1, 2\}\}\]
.Features
Two ZDDs are identical if and only if the families they represent are identical (exercise). When we refer to a family as a ZDD, we mean the ZDD representing the family, and vice versa.We can enumerate all sets in
\[F\]
lexicographically (exercise).We have
\[|F| = |F_0| + |F_1|\]
, thus we can recursively compute the number of
sets in a ZDD. This also allows us to pick out, for instance, the 13th set out
of a 42-member family (exercise). Random access is fast, and somewhat analogous
to lazy evaluation in programming languages such as Haskell: the ZDD can
produce desired family members quickly on demand. Thus any operation we can do
on an array of sets, we can do with similar efficiency on a ZDD.We can modify these techniques so that if we weight each element in the universe, after recursively visiting each node, we can find the sets in the family of maximum (or minimum) weight, and statistics such as the mean and standard deviation. We can compute interesting generating functions, such as one from which we can read off the number of sets of a given size. With an array representation of a family, we would have to visit each set. With a ZDD, we only have to visit each node, which is often much smaller.
As with data structures built from trees, we can convert recursive algorithms to iterative bottom-up algorithms. For conciseness we tend towards the former in our exposition, though the latter may be better in practice.